Die große Unbekannte
Sie vereinen Windeln und Bier, können Öl ersetzen und Liebe erkennen. Oder doch nicht? Über Daten, besser Big Data, wird viel gesprochen, aber wenig gewusst. Bevor wir in die Welt der industriellen Datennutzung eintauchen, möchten wir uns dem Thema populärwissenschaftlich nähern.

Big Data Bang
Die zunehmende Digitalisierung ist auch im Anstieg der weltweiten Datenmengen – der sogenannten Datensphäre – erkennbar. 2010 betrug das Volumen aller erzeugten, erfassten und replizierten Daten 2 Zettabyte (das ist eine Zahl mit 21 Nullen). Bis 2025 soll die Datensphäre auf stolze 181 Zettabyte anwachsen, was mehr als 90-mal so viel wie 2010 ist. Würde man diese Datenmenge auf DVDs speichern, wäre der Stapel (ohne Hüllen) etwa 9,4 Millionen Kilometer hoch – über 24-mal die Strecke von der Erde zum Mond.
Am Anfang war die Beulenpest
Das Prinzip, Daten als Quell der Erkenntnis zu sehen, ist nicht neu. Im Laufe der Jahrhunderte haben die Menschen immer wieder versucht, Informationen systematisch zur Entscheidungsfindung einzusetzen. Schon die alten Ägypter versuchten um 300 vor Christus, alle Daten in den Werken der Bibliothek von Alexandria zu erfassen. Die Römer studierten sorgfältig die Statistiken ihrer Militärs, um zu bestimmen, wie sie Streitkräfte optimal verteilen. Der erste Hinweis auf die Arbeit mit „Big Data“ im heutigen Verständnis stammt aus dem Jahr 1663. John Graunt untersuchte die Sterbeziffern in England zu Zeiten der Beulenpest, die damals Europa heimsuchte, und arbeitete dabei mit für damalige Verhältnisse überwältigenden Informationsmengen. Damit war er einer der ersten Menschen, die statistische Datenanalyse einsetzten.

Besser als Öl
Öl, Mobilfunk, Energie, Finanzen – noch 2008 machten die fünf weltweit größten Unternehmen damit ihr Geld. Heute sind vier der fünf Größten Technologieunternehmen, die teils schon rein datenbasiert oder mit Clouddiensten ihr Geld verdienen. Das zeigt für den Moment, dass Daten das bessere Öl sind: Man kann sie duplizieren, sie sind wiederverwendbar und eine nahezu unendliche Ressource.
Die dunkle Seite der KI
Amazon musste 2017 einen Algorithmus abschaffen, der unbeabsichtigt männliche Bewerber gegenüber weiblichen bevorzugte. Und ein anderer Algorithmus im US-Justizsystem berechnete über Jahre hinweg zu hohe Rückfallwahrscheinlichkeiten bei schwarzen Angeklagten und Straffälligen, sodass sie tendenziell längere Gefängnisstrafen erhielten als weiße Delinquenten und geringere Chancen hatten, auf Kaution freigesetzt zu werden. Das sind nur zwei Fälle, die andeuten: Daten und Künstliche Intelligenzen sind nicht zwangsläufig objektiv. Sie übernehmen Vorurteile ihrer Programmierer. Diese sind in der Tech- Industrie zu 80 Prozent männlich und mehrheitlich weiß, wie das Wirtschaftsmagazin Forbes berichtete. Eine wichtige Aufgabe für die Zukunft lautet daher: Mehr Diversität und weniger Vorurteile in der Datenanalyse.

Die Bier-Windel-Legende
Nicht ganz wahr, aber seit Jahrzehnten eine hilfreiche Story in Seminaren und Literatur: Der Erzählung nach soll der Handelsriese Walmart anhand der Kassenbons in den 90er-Jahren festgestellt haben, dass an Freitagabenden vermehrt Bier und Windeln gefragt waren. Junge Väter nutzten demzufolge den Wochenend-Einkauf der Familie, um sich mit ein paar Sixpacks einzudecken. Findige Mitarbeiter platzierten das Bier daraufhin nahe dem Babybedarf. Das Ergebnis: Die Verkäufe schossen in die Höhe. Auch wenn die Beteiligten selbst sagten, es habe keine Korrelation der Verkaufszahlen mit Geschlecht oder Alter der Käufer gegeben, ist der Effekt unbestritten – und das Prinzip des Data-Mining daran eindrücklich erklärbar.
Fische mit Fingern
Irren ist ein Grundpfeiler der Menschheit. Also können auch künstliche, von Menschen mit Daten gefütterte Intelligenzen auf den Holzweg geraten. Forscher der Universität Tübingen haben ein neuronales Netzwerk darauf trainiert, Bilder von Schleien zu erkennen. Doch als die Wissenschaftler wissen wollten, anhand welcher Merkmale die KI die Fische bestimmt und sich die wichtigsten Pixel dafür anzeigen ließen, kam die Überraschung: eine Auswahl rosiger menschlicher Finger vor grünem Hintergrund. Es stellte sich heraus, dass die meisten Fotos im Datensatz Angler zeigten, die Schleien in den Händen hielten. Das hatte die KI auf falsche Gedanken gebracht; sie kam zum Schluss, die Finger seien Teile des Fischs.
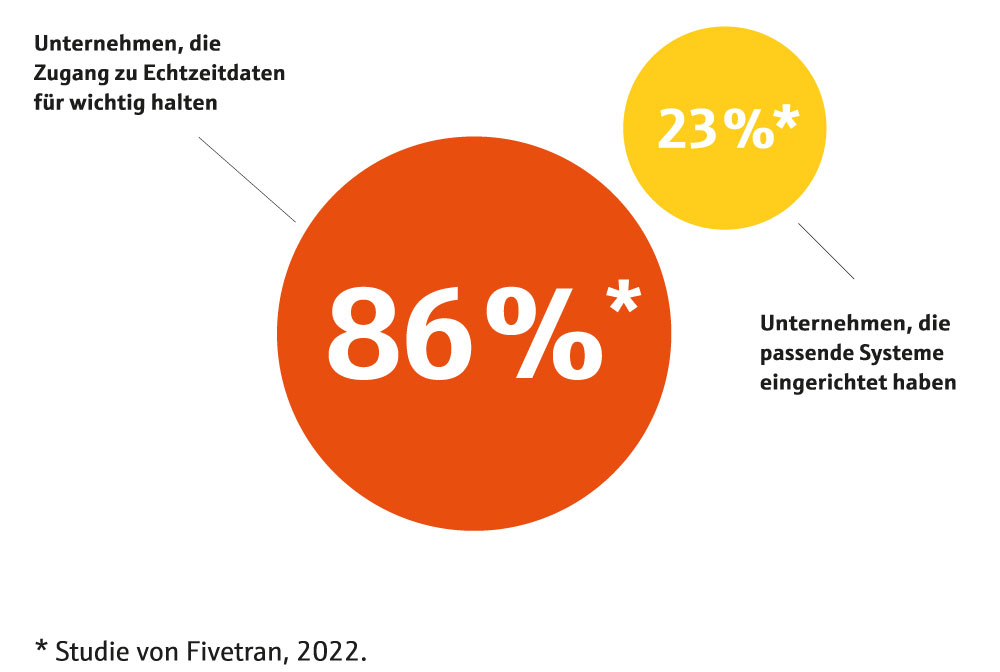
Ist schon Echtzeit?
Alle wollen es, die wenigsten können schon.
Datamatch = Liebe?
Online-Dating-Dienste boomen seit Jahren. Wie genau ihre Algorithmen funktionieren, verraten sie nicht. Die Annahme: Je ähnlicher sich zwei Menschen in ihren Werten und Vorlieben sind, desto besser stehen ihre Chancen für eine lange, glückliche Beziehung. Alles heiße Luft, finden Forscher der Northwestern University in Illinois. Im US-Fachmagazin „Psychological Science“ erläutern sie, dass Persönlichkeitstests nicht abbilden könnten, wie zwei Personen tatsächlich harmonieren oder ob der Humor stimmt. Auch werde nicht nach stressigen Lebensphasen oder finanziellen Problemen gefragt, die eine Beziehung belasten können. Nach langfristiger Liebe sollte man also besser im Real Life Ausschau halten.
„ Es ist klar, dass wir alle in einem Meer von Informationen ertrinken. Die Herausforderung besteht darin, zu lernen, in diesem Meer zu schwimmen.”
Peter Lyman (1940–2007),
Autor und Informationswissenschaftler an der University of California, Berkeley
Veröffentlicht am 14.10.2022, zuletzt aktualisiert am 21.11.2022.
Tauchen Sie mit dem Newsletter von «changes» jeden Monat durch neue spannende Geschichten in die Welt der Prozessindustrie ein!









